
AI will need editors
5 indispensable skills for surviving an economy with information overload


I’ve been thinking about editors lately. About my own editing work, and the editors I worked for.
I’ve been thinking about the great ones, like Malcolm.
This guy could smell bullshit from another area code. As a cub reporter, I’d talk to him about a story. He’d bombard me with a dozen questions: How will this person react? What’s the effect of x on y? What does the law say? Have you reached out to so and so? I’d grow annoyed. If that annoyance registered, he never showed it – instead he operated with the quiet confidence of a veteran who was perennially three steps ahead of me.
He spotted fallacies. He predicted consequences and foresaw fallout. And he knew that the red flags he raised for me at 9 a.m. would inevitably become the problems I’d be struggling with around deadline time eight hours later.
I’m grateful for everything he taught me. Because we will need these lessons for what’s coming.
So here’s my thesis today: Editing will be a superskill of the AI era, and not just editing but a related set of cognitive habits centred on critical thinking, which could easily include philosophy, the law or liberal arts.
I’ll list specific habits of successful editors in a moment. But first I want to elaborate on why I feel this way — why I think, “Learn to code,” will become, “Learn to question.”
Clearly I’m not alone in expecting this shift. AI leaders as diverse as Peter Thiel and Daniela Amodei are talking about how “word people” and humanities grads may hold more coveted skill stacks in the AI economy.
I’d like to believe this explains at least to some extent a recent pattern in Google searches: after decades of precipitous decline, searches for editors have begun inching up in recent months.
Look at this. A study that finds only workers with certain mental habits gain creativity from AI. The study calls it metacognition — I call it looking at ChatGPT outputs and being able to tell the difference between, This is great shit! and What is this shit?
Here I’ll provide specific examples from new research about why I feel this way; connect it to personal anecdotes from several months of heavy AI usage; then list those good editing habits.
Let’s begin with this new paper: Even the best AI models, including a model released just days ago, stall at only 34% accuracy in analyzing a big dataset. That’s great for a baseball batting average — but a disaster for a professional product.
These models were given U.S. Treasury bulletins going back a century, 89,000 pages, and asked 133 questions which they mostly flubbed.
Okay, let’s assume these models keep getting better. So mistakes become rarer, harder to catch. Guess what: You’ll still need someone catching them!
Now let’s take it a step further.
Let’s assume these models become perfect – let’s say we reach Artificial Super Intelligence and they wind up nailing every question, even in real-time situations that require advanced future forms of Retrieval Augmented Generation.
Spoiler: You’ll still need editors. Even in this scenario. In this perfect-genius-robot future, the world will be utterly drowning in content. Organizations will need help managing that content.
Malcolm would do this during breaking stories. He’d have reporters calling him from across the country, dictating tidbits and quotes, thousands of words of content that, if published as is, would make for an incoherent and interminable news story.
He had to assess this material and decide: a) What to keep for the story b) Where to place it in the story c) What to save for another story d) And what to throw away.
Organizations will need this role. Traffic cops for content.
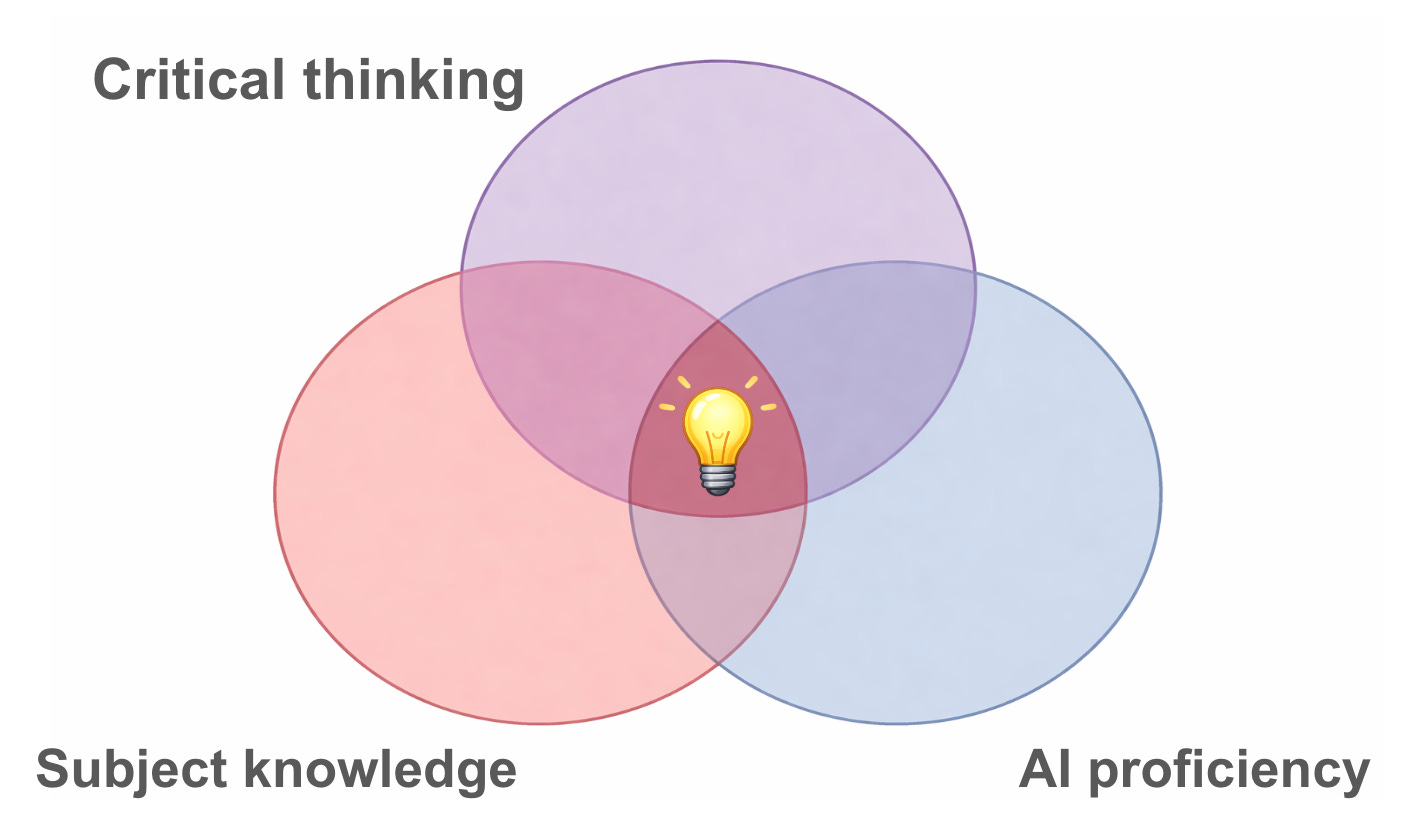
The most successful of these will be people possessing the sweet spot of three distinct skills: subject-matter knowledge + AI fluency + critical thinking.
I’ll give one example of this winning trifecta. I’m thinking of an enterprising law firm that creates some sort of app called, hypothetically, Pocket Lawyer. I suspect we’ll see very successful businesses do this.
I suspect these apps will significantly expand the market for legal services. Rendering them more affordable, and more accessible, to more people. But you can’t file hallucinated crap in court or with a regulatory agency.
So the app generates an early draft of legal documents, but you would still need human lawyers to do the final… ahem… edit.
What I’ve been experiencing
The newsroom nostalgia has been growing within me since the fall. As some may know, I worked in journalism for 28 years before going on sabbatical, during which I’m getting a master’s in AI management.
In recent months I’ve built an anti-algorithm algorithm for alternative travel, which looks for beautiful-but-less-popular sites in 194 countries; a daily briefing note on developments in AI, translated into language for non-technical professionals; a stock-market dashboard with 140 years of market data; a personalized movie-recommendation-algorithm; and a bunch of video games.
And the point I want to make here is: You have no idea how many screwups I averted. Some big ones, too!
Some were basic. Take the travel app. It took me weeks to build that app, with AI tools last year that weren’t as good. I’d think it was almost ready, then I’d run some spot checks, and I’d be like, “Hey, why are the Spanish regional unemployment numbers different in my app’s master dataset from the ones in the spreadsheet I gave you?”
And the AI would be like: Oh, yeah, made that up. There were days I wanted to fling my laptop across the room.
Suddenly, a couple of months ago, we crossed a threshold. The mistakes grew rarer. As the tools improved, the success rate grew. This is part of what drove my conversion to Claude Code, powered by Claude’s Opus 4.5 model.
But guess what? Claude Code still screws up. And this is a critical point: it screws up in harder-to-catch ways. More sophisticated tools, it turns out, make more sophisticated mistakes.
I’ll give you a near-comical example – but first, a quick primer on Machine Learning. The basic idea of ML is you feed data to a machine (your training data). The machine looks for patterns in the data, then makes predictions. You test those predictions on a separate dataset (your testing data). You measure the average error size. Say you’re doing weather predictions — you miss by 4C on the first test. You run a second test, and miss by 3C. Then it’s 2.7C on the third run. You keep repeating until the error stops shrinking. That’s Machine Learning. It’s the loop that powers many tools you use.
Claude Code and other new models can do this. You can literally say: Do Machine Learning to predict the weather. It will download a ML library like scikit-learn and find the required climate data, and start running projections.
So what I did the other day was point it at data to measure the effects of AI on the job market. I wanted to know: By age group, education level, industry, and geographic location – what is AI doing? I uploaded data from the U.S. Bureau of Labor Statistics.
Claude came back within minutes with extraordinary charts. Troubling charts, dramatic charts, showing a plunge in postings for young professional positions. It even produced a lengthy briefing note.
Then I asked: Hey, if a data scientist or economist wanted to test these numbers, are they reproducible? Give me a step-by-step guide to how you got here.
And it admitted: This. Was. All. Junk. Well, not in so many words, but what it did was combine news articles – news articles! – with the BLS data to make completely non-scientific projections. Needless to say, Machine Learning does not involve tossing Forbes pieces into your dataset.
We started over. This time it produced step-by-step documentation, with far less dramatic results. It also apologized profusely.
The point here is that the errors are increasingly hard to detect. This is not the ChatGPT of 2022 hallucinating a quote – where you can check Google and see instantly if it’s real.
The world is about to be submerged in this crap: synthetic data everywhere, creeping into news articles, influencer posts, LinkedIn, X, academic studies – some of it accurate, some of it not.
It’s going to contaminate our information ecosystem, and our workplaces. And I repeat myself here: even if this problem disappears, which I doubt, we will still encounter the problem of information overload – we will all be editors, at that metaphorical desk, playing traffic cop with an endless stream of content.
In apologizing to me, the AI itself, Claude Code, essentially admitted: I need an editor. So what exactly are these things an editor looks for?
Things an editor asks
What’s the story? The world produces 400 terabytes of data per day and it’s growing fast. We are drowning in detail. Nowadays, you could theoretically create transcripts for everything your organization does: every call, meeting, sales record, document, and use it to create new stuff. Then key is deciding: What do you want to communicate from this? Put differently: What’s the story? The story you want to tell your staff, the public, or yourself. That’s your starting point. Understanding that objective guides what questions you ask the AI, what documents you preserve, and what you ultimately create. Take my stock-market dashboard – I wanted a clear takeaway atop the dashboard. I had gathered a bunch of metrics that historically foreshadow market shifts. Originally, it was a muddled mess. I deleted data that cluttered up the page without adding value. And I picked that bright red font with the big number at the top – to emphasize the key takeaway. In news lingo, that was the lead (The lead is… we’re due for a major stock-market crash, if history holds). I pushed the supporting details lower down the page, and deleted what I didn’t need.
What’s your source? Show, ask, check. You know the old expression: Garbage in, garbage out. Put another way: You are what you eat. AI eats data – numbers, text, and with those it creates outputs. Here are three ways to encourage healthy sourcing. One is transparency. Show your source. In news stories, we attribute them: he said/she said/the document said. AI products should have similar sourcing disclaimers. This helps your reader assess the quality, and there’s a simultaneously benefit — it creates pressure on you: you, the journalist, or in this case the AI user, know you will be scrutinized. This forces an incentive to seek quality sourcing — built-in pressure toward best practices. But sourcing isn’t always clear. The second way to encourage quality sourcing is to ask the machine. Hey, where did you get that? A good editor sees when stories have no sourcing, or anonymous sourcing, and asks: Who told you this? Do the same with your LLM. This allows you to check the record. With the sourcing info handy, you perform the third and final step: double-checking the source material. My old instinct to check has saved my skin a few times lately – otherwise I might have published a travel app with made-up data and junk charts on job losses. Show, ask, check.
Consider the counter-argument. Editors learn to do this in their sleep. It’s drilled into political reporters too: If I write X, someone will argue Y. Guess what? Sometimes Y is right and you’re wrong. Test your hypothesis before publishing – not after. I recall the advent of political blogging two decades ago. In some ways, it was great for journalism. We started getting grief for every stupid little sentence we wrote. Bloggers would rip our stories to shreds. This never happened before and, frankly, I can’t say it was fun. But it made us better. It made reporters think twice before pulling a hypothesis from our posteriors. So remember: Is there another possible explanation? If you aren’t sure, say so. Take this blog post, for example. See that factoid about rising Google searches for editors? There’s a reason I adorned it with a Christmas tree’s worth of qualifiers.
What’s the baseline? Ah, the dirtiest trick in journalism: cheating on the denominator. Before you present a measurement, you must choose what to measure. And here’s a nasty little secret: you can make pretty much anything look good, or bad, depending on what you choose. Carbon emissions. Crime stats. Middle East hostilities. Take your pick. You can draw different conclusions based on your chosen baseline. Compare current crime to a high-crime year (1991) and the world is a safe, cozy place; compare it to a low-crime year (1955, 2015) and you have people putting bars on the windows. All with the same stats! People do this all the time — with GHG emissions, and pretty much any contentious topic. They compare current data to their favorite baseline. Good editors know this – and they know to press their reporters on it. This is highly relevant when presenting research using AI. Again, let’s use the Google Trends chart on editors as an example. I could have told three different stories, based on my baseline: A positive one, a negative one, or a complete one. Let’s say we compared today’s search data to 2024, you’d think searches for editors have soared to dramatic highs based on the last year. But zoom out to 2004 and you’ll see we are still mired in a long-term historic trough, just barely starting to climb back. I tried doing the responsible thing here. I searched for both short- and long-term timeframes — and I mentioned both. I tried telling the most complete story I could. Do the same with your machine: Test its output across different time horizons. Say you’re creating a visual dashboard. You need to know what comparisons to make. The best practice is to test different baselines.
Did you keep your notes? Documentation. This is to 2026 LLM use what prompt-writing was to 2022. It’s part of the shift to agentic AI. Now I’m rediscovering old instincts — the old instinct to collect notepads. For years, the advent of Google trained me to assume I could find most facts I needed online, so I became less methodical in preserving notes. I’ve now snapped back to old habits. The cause was Claude Code. Agentic AI will produce himalayan heaps of data from your command terminal, but it has a defective memory. You’ll be like: “Hey, we need to adjust the website. Go back in, use the login, and fix,” and agentic AI will be like, “What website?” So I create folders for every project. For any project, my very first request is to create a file in that folder called something like BRIEFING NOTE. I keep updating that file. This file winds up logging every major action from every session, and describes our workflow. This way I can start a session and say, “Here, fix this website,” and I drop the file into the chat. Here’s another benefit to keeping records, which has nothing to do with speeding up your prompting: Fact-checking. Proper documentation lets you scrutinize your work later, as illustrated by my recent episode involving jobs data. Records allow testing. Testing allow accuracy. All of it enables transparency.
The kinds of things I ask Claude Code
This brings me back to journalism. With a lesson I learned as a youngster, about consequences. And about preparing to face them — with documentation. You can be sued for what you write, and if that happens you may need evidence in court. If you’re sued for libel, there’s no better defense than pointing to the tape and saying: Actually, here’s exactly what you said. You’ve kept a record.
I think I put Malcolm through a few of these moments. And I’m forever grateful for what he gave me back – for what he, and other editors, taught me. We’re going to need these lessons, badly.
All of this! The other skillset that I think is going to be useful in this new paradigm is having basic understanding of data coding languages -- say R or python. And I don't mean master coding -- I mean, being able to read and spot logic and errors.
In this new AI workflow, I see two new spots where we'll need human intervention: (1) The critical assessment (edit) that you note; and (2) verification (objective checks).
I've found that asking for Claude to spit out AND annotate R scripts (for a beginner R coder; along w/ some annotations explaining statistical concepts) for data projects I'm working on that would have previously been beyond my coding skillset is useful, and then I run the actual R script myself, in stages, and work through the comments. This obviously slows me down right now, but I'm also improving my own verification skillset along the way.
Thanks for this well crafted timely wake-up call. It reflects that combination of documented information and 'what to do about it' that I have respected in your reporting over the years.
Even though this posting indicates you don't need it, "Good luck on the Degree". I look forward to hearing you back as a new double expert on panel discussions.